基于Ollama和OpenClaw实现100%本地化部署AI助手的完整指南,涵盖环境准备、模型部署、多模型切换及Telegram对接,确保免费、断网可用、灵活扩展的特性。内容综合多篇实践文档,关键步骤均附引用来源。
完全本地化
数据无需上传云端,隐私零泄露,断网环境下仍可运行。
通过Ollama管理本地模型(如Qwen3、GPT-OSS等),OpenClaw负责任务调度,形成闭环链路。
多模型自由切换
支持主流开源模型(Qwen3、GLM-4.7、GPT-OSS等),通过修改配置文件即可切换。
硬件友好
最低配置:16GB内存(MacOS)或GPU服务器(如NVIDIA显卡);推荐32GB以上内存+GPU加速。
Git(Windows管理员权限执行):
Ollama客户端:
官网下载安装包(https://ollama.com/download)或命令行安装(Linux):

推荐模型(需64k以上上下文窗口):
| 模型名称 | 特点 | 下载命令 |
|---|---|---|
qwen3-coder | 编码任务优化 | ollama pull qwen3-coder |
gpt-oss:20b | 平衡性能与速度 | ollama pull gpt-oss:20b |
glm-4.7 | 通用能力强 | ollama pull glm-4.7 |
通用命令:
curl -fsSL https://openclaw.ai/install.sh | bash
Windows专用:
iwr -useb https://openclaw.ai/install.ps1 | iex
启动服务:
ollama launch openclaw
配置文件修改(关键步骤):
编辑\~/.openclaw/openclaw.json,指定Ollama的本地API地址(如http://127.0.0.1:11434/v1)和模型ID:
{
"models": {
"providers": {
"ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"apiKey": "任意字符串(如ollama-local)",
"models": [{"id": "qwen3", "name": "Qwen3"}]
}
}
},
"agents": {
"defaults": {
"model": {"primary": "ollama/qwen3"}
}
}}注意:api字段需设为openai-completions,否则可能无法响应。
切换模型:
修改配置文件中的id和name字段,例如从qwen3改为gpt-oss:20b,重启服务生效。
验证部署:
访问http://localhost:18789?token=配置中的token,输入问题测试回复是否来自本地模型。
创建Bot:
通过@BotFather申请新机器人,获取Token(如8123121125:AAExamegv-0FQCfhfbazmp4405V0XAJCKfk)[用户提供]。
配对OpenClaw:
在Powershell中执行(替换配对码):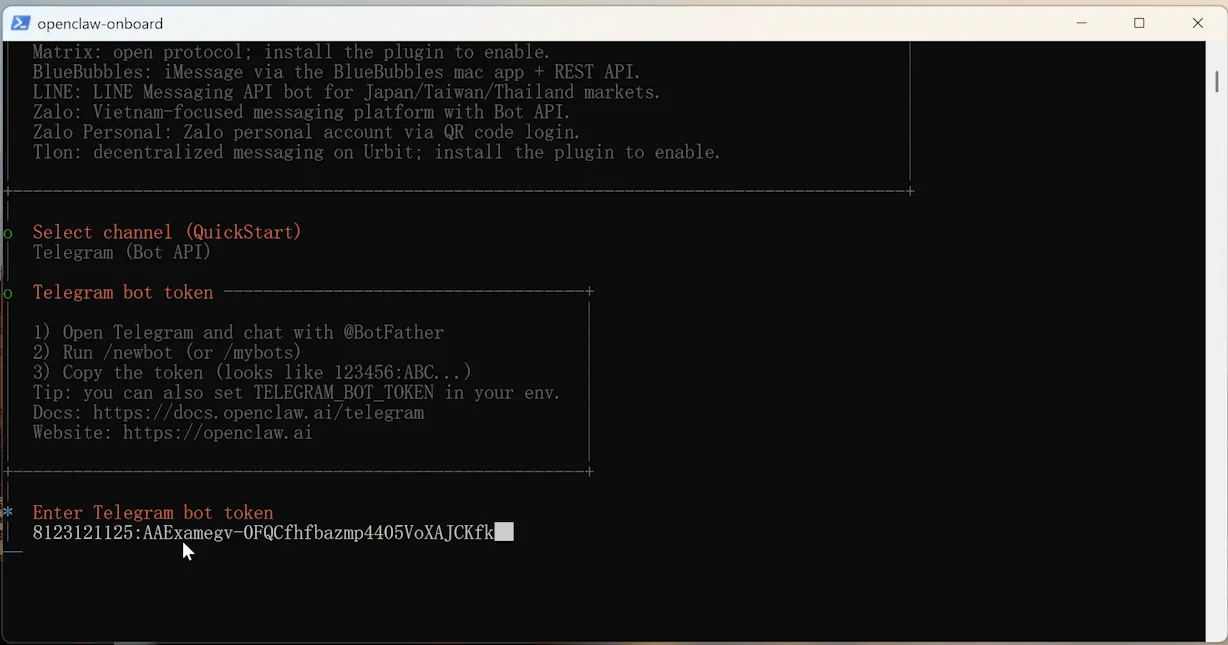
openclaw pairing approve telegram DLW7HQ69
重启服务:
ollama launch openclaw
GPU加速:若使用NVIDIA显卡,需安装nvidia-container-toolkit并配置Docker。
性能调优:调整contextWindow和maxTokens参数以匹配硬件能力。
安全部署:建议Docker容器以非root用户运行,挂载只读文件系统。

相关推荐
")
☕ 吐槽:看个收益,至于看 5 秒广告吗?作为一个老基民,我最烦的就是每天打开支付宝或天天基金时,先要忍受 5 秒钟的开屏广告,然后在一堆“热门推荐”、“理财课”的红点里找自己的收益数据。对于追求效率...

做汇报最痛苦的从来不是“写内容”,而是那些脏活累活:找模板、调字体、对齐图标、把 Excel 截图塞进去……一晚上过去了,PPT 还是丑得让人心碎。今天推荐的 SlideBot (2.0),...

🤔 还在给 ElevenLabs 交“月供”?做视频、做播客的朋友都知道,ElevenLabs 效果是好,但那是真的贵。按字符收费,稍微改几个字,几美刀就没了。而且,要把自己的声音传到别人云端服务器,...

最近参加各个科技论坛、峰会,遇到不少同行,我发现大家都乐观了起来,因为,在这波科技股AI 浪潮中赚到钱了。都说三根大阳线改变信仰,这次AI 热潮的大阳线可不止三根。比起小打小闹的散户,科技大厂们在这波...

一夜之间,甲骨文就从垂垂老矣的数据库公司变成AI巨擘,以及成为未来TikTok 股权交易的最大赢家。美东时间9 月15 日,甲骨文股价再度上涨3.41%。此前八月,它就被美国私人金融和投资咨询公司Mo...

近两年,以大模型为代表的AI行业,其迭代速度之快,已经远超我们想象。昨日还是聚光灯下的行业明星,明日可能就不得不黯然退场。近日,AI智能体明星公司Manus突然清空其国内社交平台的所有内容。有媒体爆料...

DeepSeek很热,但它对企业的大影响还没全面到来。” “许多企业拥抱AI,还要补数字化的课。” “智能体归根结底是一个软件,规模化应用要有信息化基础” “所有企业都应该开发知识库和智能问答系...

来源:巨潮WAVE作为全球科技领域金字塔顶尖的产业,如今的“全球芯片五巨头”全都由华人掌管。随着英特尔新CEO走马上任,陈福阳、黄仁勋、陈立武、苏姿丰、魏哲家分别主导博通、英伟达、英特尔、AMD和台积...